Nutch for the Version 1.5.0 and 1.5.1
1. Edit conf/nutch-site.xml and add the following in between the <configuration>-clauses:
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>http.robots.agents</name>
<value>nutch-solr-integration-test,*</value>
<description></description>
</property>
<property>
<name>http.agent.name</name>
<value>nutch-solr-integration-test</value>
<description>Viterbi Bot</description>
</property>
<property>
<name>http.agent.description</name>
<value>Viterbi Web Crawler using Nutch 1.0</value>
<description></description>
</property>
<property>
<name>http.agent.url</name>
<value>http://www.thehindu.com/</value>
<description></description>
</property>
<property>
<name>http.agent.email</name>
<value>venkatkandasamy@gmail.com</value>
<description></description>
</property>
<property>
<name>http.agent.version</name>
<value></value>
<description></description>
</property>
<property>
<name>generate.max.per.host</name>
<value>100</value>
</property>
</configuration>
2. You need to insert domain into _conf/regex-urlfilter.txt:
You need to insert domain into _conf/regex-urlfilter.txt:
# allow urls in viterbi.usc.edu domain
+^http://([a-z0-9\-A-Z]*\.)*viterbi.usc.edu/([a-z0-9\-A-Z]*\/)*
# deny anything else
-.
**Important: Make sure that you
Edit this:
# accept anything else
+.
To this:
# accept anything else
#+.
eg:
# accept anything else
#+.
+^http://([a-z0-9]*\.)*thehindu.com/
3.Now, we need to instruct the crawler where to start crawling, so create a seed list:
mkdir urls
echo "http://viterbi.usc.edu/" > urls/seed.txt
mkdir urls
echo "http://viterbi.usc.edu/" > urls/seed.txt
4.Start by injecting the seed url(s) to the nutch crawldb:
bin/nutch inject crawl/crawldb urls
5.Next, generate fetch list:
bin/nutch generate crawl/crawldb crawl/segments
6. The above command generated a new segment directory under /usr/share/nutch/crawl/segments that contains the urls to be fetched. All following commands require accessing the latest segment directory as their main parameter so we’ll store it in an environment variable:
export SEGMENT=crawl/segments/`ls -tr crawl/segments|tail -1`
7. Launch the crawler!
bin/nutch fetch $SEGMENT -noParsing
or bin/nutch fetch $SEGMENT -noParsing
8. And parse the fetched content:
bin/nutch parse $SEGMENT
9. Now we need to update the crawl database to ensure that for all future crawls, Nutch only checks the already crawled pages, and only fetches new and changed pages.
bin/nutch updatedb crawl/crawldb $SEGMENT -filter -normalize
10. Create a link database:
bin/nutch invertlinks crawl/linkdb -dir crawl/segments
**Important:
The more number of times you repeat above crawling steps you will get better crawl depth!
bin/nutch inject crawl/crawldb urls
5.Next, generate fetch list:
bin/nutch generate crawl/crawldb crawl/segments
6. The above command generated a new segment directory under /usr/share/nutch/crawl/segments that contains the urls to be fetched. All following commands require accessing the latest segment directory as their main parameter so we’ll store it in an environment variable:
export SEGMENT=crawl/segments/`ls -tr crawl/segments|tail -1`
7. Launch the crawler!
bin/nutch fetch $SEGMENT -noParsing
or bin/nutch fetch $SEGMENT -noParsing
8. And parse the fetched content:
bin/nutch parse $SEGMENT
9. Now we need to update the crawl database to ensure that for all future crawls, Nutch only checks the already crawled pages, and only fetches new and changed pages.
bin/nutch updatedb crawl/crawldb $SEGMENT -filter -normalize
10. Create a link database:
bin/nutch invertlinks crawl/linkdb -dir crawl/segments
**Important:
The more number of times you repeat above crawling steps you will get better crawl depth!
----------------------------------------------------------
1. bin/nutch readdb crawl/crawldb -stats
CrawlDb statistics start: crawl-20120817130305/crawldb
Statistics for CrawlDb: crawl-20120817130305/crawldb
TOTAL urls: 74
retry 0: 74
min score: 0.01
avg score: 0.026202703
max score: 1.0
status 1 (db_unfetched): 73
status 2 (db_fetched): 1
CrawlDb statistics: done
2. bin/nutch readdb crawl/crawldb -dump venkat3
2. bin/nutch readdb crawl/crawldb -dump venkat3
http://epaper.thehindu.com/ Version: 7
Status: 1 (db_unfetched)
Fetch time: Fri Dec 07 18:55:53 IST 2012
Modified time: Thu Jan 01 05:30:00 IST 1970
Retries since fetch: 0
Retry interval: 2592000 seconds (30 days)
Score: 0.010989011
Signature: null
Metadata:
http://www.thehindu.com/ Version: 7
Status: 2 (db_fetched)
Fetch time: Sun Jan 06 18:55:14 IST 2013
Modified time: Thu Jan 01 05:30:00 IST 1970
Retries since fetch: 0
Retry interval: 2592000 seconds (30 days)
Score: 1.0
Signature: 70e4d4b9696e3f479898cd247cec9825
Metadata: Content-Type: application/xhtml+xml_pst_: success(1), lastModified=0
3. bin/nutch readlinkdb crawl/linkdb -dump venkat
o/p:
http://epaper.thehindu.com/ Inlinks:
fromUrl: http://www.thehindu.com/ anchor: ePaper
http://m.thehindu.com/ Inlinks:
fromUrl: http://www.thehindu.com/ anchor: Mobile
4. bin/nutch readseg -dump /usr/local/nutch/nutch1.5/crawl/segments/20121207185455 venkat2
o/p:
o/p:
Recno:: 0
URL:: http://epaper.thehindu.com/
CrawlDatum::
Version: 7
Status: 67 (linked)
Fetch time: Fri Dec 07 18:55:36 IST 2012
Modified time: Thu Jan 01 05:30:00 IST 1970
Retries since fetch: 0
Retry interval: 2592000 seconds (30 days)
Score: 0.010989011
Signature: null
Metadata:
Recno:: 2
URL:: http://www.thehindu.com/
CrawlDatum::
Version: 7
Status: 65 (signature)
Fetch time: Fri Dec 07 18:55:36 IST 2012
Modified time: Thu Jan 01 05:30:00 IST 1970
Retries since fetch: 0
Retry interval: 0 seconds (0 days)
Score: 0.0
Signature: 70e4d4b9696e3f479898cd247cec9825
Metadata:
CrawlDatum::
Version: 7
Status: 1 (db_unfetched)
Fetch time: Fri Dec 07 18:54:27 IST 2012
Modified time: Thu Jan 01 05:30:00 IST 1970
Retries since fetch: 0
Retry interval: 2592000 seconds (30 days)
Score: 1.0
Signature: null
Metadata: _ngt_: 1354886687330
Content::
Version: -1
url: http://www.thehindu.com/
base: http://www.thehindu.com/
contentType: application/xhtml+xml
metadata: x-varnish-server=CHNHINWCA02 Content-Language=en Age=98 Content-Length=29793 _fst_=33 nutch.segment.name=20121207185455 Set-Cookie=BIGipServerWEBPOOL_80=4038139914.20480.0000; path=/ Connection=close Server=Apache-Coyote/1.1 X-Cache=HIT Vary=Accept-Encoding Date=Fri, 07 Dec 2012 13:25:17 GMT Content-Encoding=gzip nutch.crawl.score=1.0 Accept-Ranges=bytes Content-Type=text/html;charset=UTF-8
Content:
<< html page >>
ParseData::
Version: 5
Status: success(1,0)
Title: The Hindu : Home Page News & Features
Outlinks: 91
outlink: toUrl: http://www.thehindu.com/todays-paper/ anchor: Today's Paper
outlink: toUrl: http://epaper.thehindu.com/ anchor: ePaper
.
.
.
outlink: toUrl: http://www.thehindu.com/news/cities/Hyderabad/ anchor: Hyderabad
Content Metadata: x-varnish-server=CHNHINWCA02 Content-Language=en Age=98 Content-Length=29793 _fst_=33 nutch.segment.name=20121207185455 Set-Cookie=BIGipServerWEBPOOL_80=4038139914.20480.0000; path=/ Connection=close Server=Apache-Coyote/1.1 X-Cache=HIT nutch.content.digest=70e4d4b9696e3f479898cd247cec9825 Vary=Accept-Encoding Date=Fri, 07 Dec 2012 13:25:17 GMT Content-Encoding=gzip nutch.crawl.score=1.0 Accept-Ranges=bytes Content-Type=text/html;charset=UTF-8
Parse Metadata: CharEncodingForConversion=utf-8 OriginalCharEncoding=utf-8
CrawlDatum::
Version: 7
Status: 33 (fetch_success)
Fetch time: Fri Dec 07 18:55:14 IST 2012
Modified time: Thu Jan 01 05:30:00 IST 1970
Retries since fetch: 0
Retry interval: 2592000 seconds (30 days)
Score: 1.0
Signature: null
Metadata: _ngt_: 1354886687330Content-Type: application/xhtml+xml_pst_: success(1), lastModified=0
ParseText::
<< Parsed html text >>
Recno:: 3
URL:: http://www.thehindu.com/arts/
CrawlDatum::
Version: 7
Status: 67 (linked)
Fetch time: Fri Dec 07 18:55:36 IST 2012
Modified time: Thu Jan 01 05:30:00 IST 1970
Retries since fetch: 0
Retry interval: 2592000 seconds (30 days)
Score: 0.010989011
Signature: null
Metadata:
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
content folder :
Recno:: 0
URL:: http://www.thehindu.com/
Content::
Version: -1
url: http://www.thehindu.com/
base: http://www.thehindu.com/
contentType: application/xhtml+xml
metadata: x-varnish-server=CHNHINWCA02 Content-Language=en Age=98 Content-Length=29793 _fst_=33 nutch.segment.name=20121207185455 Set-Cookie=BIGipServerWEBPOOL_80=4038139914.20480.0000; path=/ Connection=close Server=Apache-Coyote/1.1 X-Cache=HIT Vary=Accept-Encoding Date=Fri, 07 Dec 2012 13:25:17 GMT Content-Encoding=gzip nutch.crawl.score=1.0 Accept-Ranges=bytes Content-Type=text/html;charset=UTF-8
Content:
<< html pages source >>
crawl_fetch folder :
URL:: http://www.thehindu.com/
CrawlDatum::
Version: 7
Status: 33 (fetch_success)
Fetch time: Fri Dec 07 18:55:14 IST 2012
Modified time: Thu Jan 01 05:30:00 IST 1970
Retries since fetch: 0
Retry interval: 2592000 seconds (30 days)
Score: 1.0
Signature: null
Metadata: _ngt_: 1354886687330
Content-Type: application/xhtml+xml_pst_: success(1), lastModified=0
Recno:: 0
URL:: http://www.thehindu.com/
CrawlDatum::
Version: 7
Status: 1 (db_unfetched)
Fetch time: Fri Dec 07 18:54:27 IST 2012
Modified time: Thu Jan 01 05:30:00 IST 1970
Retries since fetch: 0
Retry interval: 2592000 seconds (30 days)
Score: 1.0
Signature: null
Metadata: _ngt_: 1354886687330
crawl_parse folder :
Recno:: 0
URL:: http://epaper.thehindu.com/
CrawlDatum::
Version: 7
Status: 67 (linked)
Fetch time: Fri Dec 07 18:55:36 IST 2012
Modified time: Thu Jan 01 05:30:00 IST 1970
Retries since fetch: 0
Retry interval: 2592000 seconds (30 days)
Score: 0.010989011
Signature: null
Metadata:
Recno:: 1
URL:: http://m.thehindu.com/
CrawlDatum::
Version: 7
Status: 67 (linked)
Fetch time: Fri Dec 07 18:55:36 IST 2012
Modified time: Thu Jan 01 05:30:00 IST 1970
Retries since fetch: 0
Retry interval: 2592000 seconds (30 days)
Score: 0.010989011
Signature: null
Metadata:
Recno:: 2
URL:: http://www.thehindu.com/
CrawlDatum::
Version: 7
Status: 65 (signature)
Fetch time: Fri Dec 07 18:55:36 IST 2012
Modified time: Thu Jan 01 05:30:00 IST 1970
Retries since fetch: 0
Retry interval: 0 seconds (0 days)
Score: 0.0
Signature: 70e4d4b9696e3f479898cd247cec9825
Metadata:
Recno:: 0
URL:: http://www.thehindu.com/
ParseData::
Version: 5
Status: success(1,0)
Title: The Hindu : Home Page News & Features
Outlinks: 91
outlink: toUrl: http://www.thehindu.com/todays-paper/ anchor: Today's Paper
outlink: toUrl: http://epaper.thehindu.com/ anchor: ePaper
.
.
.
outlink: toUrl: http://www.thehindu.com/life-and-style/ anchor: Life & Style
Content Metadata: x-varnish-server=CHNHINWCA02 Content-Language=en Age=98 Content-Length=29793 _fst_=33 nutch.segment.name=20121207185455 Set-Cookie=BIGipServerWEBPOOL_80=4038139914.20480.0000; path=/ Connection=close Server=Apache-Coyote/1.1 X-Cache=HIT nutch.content.digest=70e4d4b9696e3f479898cd247cec9825 Vary=Accept-Encoding Date=Fri, 07 Dec 2012 13:25:17 GMT Content-Encoding=gzip nutch.crawl.score=1.0 Accept-Ranges=bytes Content-Type=text/html;charset=UTF-8
Parse Metadata: CharEncodingForConversion=utf-8 OriginalCharEncoding=utf-8
Recno:: 0
URL:: http://www.thehindu.com/
ParseText::
<< html parsed data >>
2. bin/nutch readseg -dump crawl/segments/* arifn
3. bin/nutch readseg -dump crawl/segments/* arifn -nocontent -nofetch -nogenerate -noparse -noparsedata
Useful Sites
2. https://sites.google.com/site/profileswapnilkulkarni/tech-talk/howtoinstallnutchandsolronubuntu1004
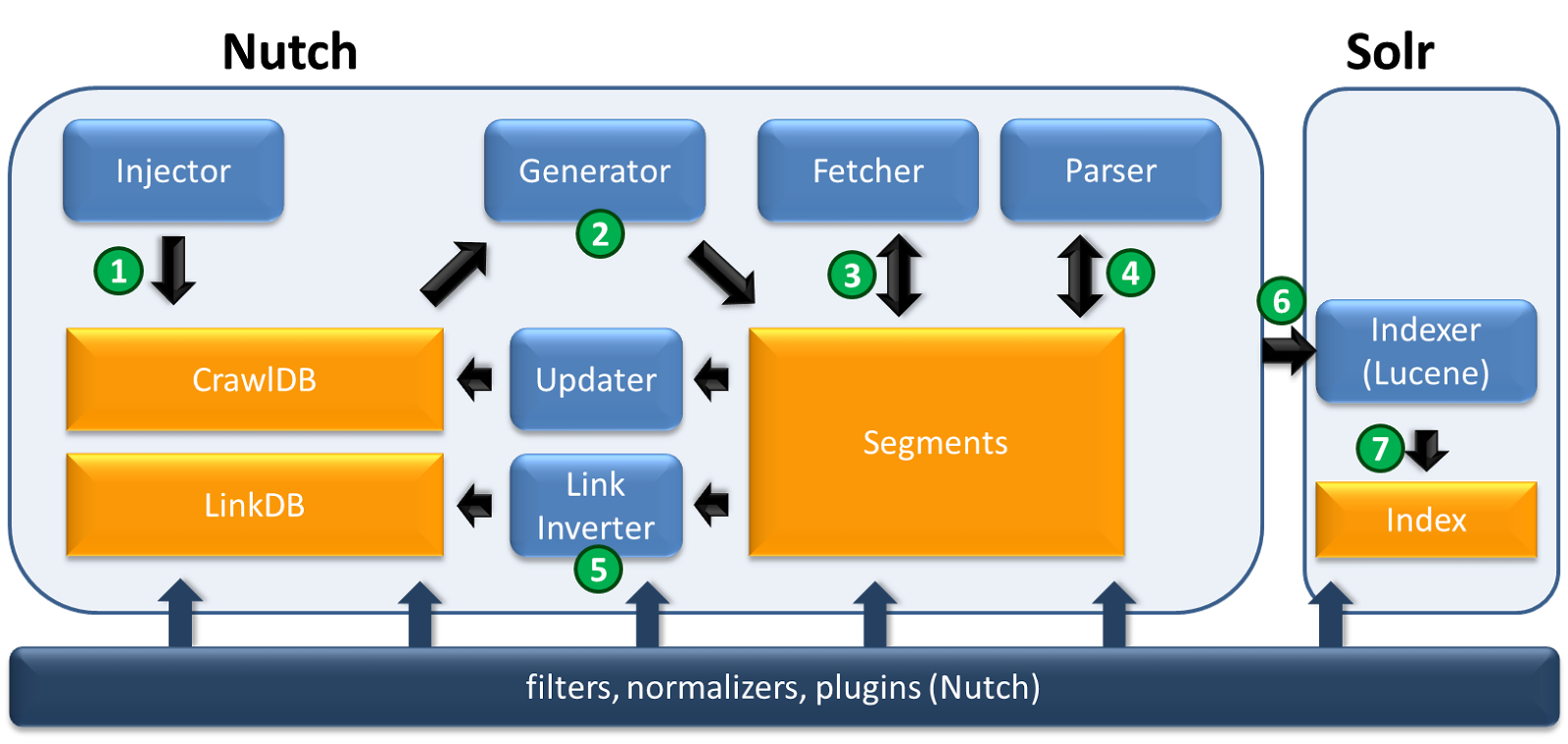
Nutch Commands
crawl
org.apache.nutch.crawl.Crawl
inject
org.apache.nutch.crawl.Injector
generate
org.apache.nutch.crawl.Generator
freegen
org.apache.nutch.tools.FreeGenerator
fetch
org.apache.nutch.fetcher.Fetcher
parse
org.apache.nutch.parse.ParseSegment
readdb
org.apache.nutch.crawl.CrawlDbReader
mergedb
org.apache.nutch.crawl.CrawlDbMerger
readlinkdb
org.apache.nutch.crawl.LinkDbReader
readseg
org.apache.nutch.segment.SegmentReader
mergesegs
org.apache.nutch.segment.SegmentMerger
updatedb
org.apache.nutch.crawl.CrawlDb
invertlinks
org.apache.nutch.crawl.LinkDb
merginkdb
org.apache.nutch.crawl.LinkDbMerger
solrindex
org.apache.nutch.indexer.solr.SolrIndexer
solrdedup
org.apache.nutch.indexer.solr.SolrDeteDuplicates
solrclean
org.apache.nutch.indexer.solr.SolrClean
parsechecker
org.apache.nutch.parse.ParserChecker
indexchecker
org.apache.nutch.indexer.IndexingFiltersChecker
domainstats
org.apache.nutch.util.domain.DomainStatistics
webgraph
org.apache.nutch.scoring.webgraph.WebGraph
linkrank
org.apache.nutch.scoring.webgraph.LinkRank
scoreupdater
org.apache.nutch.scoring.webgraph.ScoreUpdater
nodedumper
org.apache.nutch.scoring.webgraph.NodeDumper
plugin
org.apache.nutch.plugin.PluginRepository
junit
junit.textui.TestRunner
- -nocontent: Pass this to ignore the content directory.
- -nofetch: To ignore the crawl_fetch directory.
- -nogenerate: To ignore the crawl_generate directory.
- -noparse: To ignore the crawl_parse directory.
- -noparsedata: To ignore the parse_data directory.
- -noparsetext: To ignore the parse_text directory.
Fetcher.java
public class Fetcher extends Configured implements Tool, MapRunnable<Text, CrawlDatum, Text, NutchWritable>
{
Inner Classes
1. public static class InputFormat extends SequenceFileInputFormat<Text, CrawlDatum>
2. private static class FetchItem {}
3. private static class FetchItemQueue {}
4. private static class FetchItemQueues {}
5. private static class QueueFeeder extends Thread {}
6. private class FetcherThread extends Thread {}
Methods
1. private void updateStatus(..)
2. private void reportStatus(..)
3. public void configure(JobConf job)
4. public void close()
5. public static boolean isParsing(Configuration conf)
6. public static boolean isStoringContent(Configuration conf)
7. public void run(..)
8. public void fetch(Path segment, int threads)
9. public static void main(String[] args)
10. public int run(String[] args)
11. private void checkConfiguration()
}
- FetchItem = This class described the item to be fetched.
eg.
url ==?http://www.dinakaran.com/
u ==?http://www.dinakaran.com/
datum ==?Version: 7
Status: 1 (db_unfetched)
Fetch time: Sun Dec 16 22:28:02 IST 2012
Modified time: Thu Jan 01 05:30:00 IST 1970
Retries since fetch: 0
Retry interval: 2592000 seconds (30 days)
Score: 1.0
Signature: null
Metadata: _ngt_: 1355677334674
queueID ==?http://www.dinakaran.com
outlinkDepth ==?0
- FetchItemQueue = This class handles FetchItems which come from the same host ID (be it a proto/hostname or proto/IP pair). It also keeps track of requests in progress and elapsed time between requests
- FetchItemQueues = Convenience class - a collection of queues that keeps track of the total number of items, and provides items eligible for fetching from any queue.
- FetcherThread(s) = many consumers, This class picks items from queues and fetches the pages.
1. Main(..)
|
2. public int run(String[] args)
|
3. call fetch(segment, threads);
|
4. public void fetch(Path segment, int threads)
{
call checkConfiguration() back to same method
call Fetcher class run() method ===> 5
}
==>5. run(..) method in Fetcher class
{
feeder = new QueueFeeder(input, fetchQueues, threadCount * queueDepthMuliplier); <===>6
new FetcherThread(getConf()).start(); ===>7
}
===>7 FetcherThread()
{
public FetcherThread(Configuration conf) {...}
public void run()
{
while(true)
{
}
}
}
No comments:
Post a Comment